8. 阅读书摘 book excerpt¶
本篇文字标题
###################################################################
第几章
*******************************************************************
第几节
===================================================================
第几小节
-------------------------------------------------------------------
| 行符号(换行符)
* 无序列表
#. 有序列表
列表写法除了用“*”,还可以用:“-”,“+”,最后效果一样。
上面说的是无序列表,如果想用有序列表,可以用“#.”。
插入图片
rst如下:
.. image:: images/ball1.gif
8.1. 王垠博客文摘¶
8.1.1. 世界观¶
8.1.1.1. 用户友好、系统界面 抽象 接口¶
我们可以把机器和人看作同一个系统:
- 这个系统有多个模块,包括机器模块和人类模块。
- 机器模块之间的界面使用通常的程序接口。
- 人机交互的界面就是机器模块和人类模块之间的接口。
- 每个界面必须提供一定的抽象,用于防止使用者得到它不该知道的细节。这个使用者可能是机器模块,也可能是人类模块。
- 抽象使得系统具有可扩展性。因为只要界面不变,模块改动之后,它的使用者完全不用修改。
在机器的各个模块间,抽象表现为函数或者方法的类型(type),程序的模块(module)定义,操作系统的系统调用(system call),等等。但是它们的本质都是一样的:他们告诉使用者“你能用我来干什么”。
很多程序员都会注意到这些机器界面的抽象,让使用者尽量少的接触到实现细节。可是他们却往往忽视了人和机器之间的界面。也许他们没有忽视它,但是他们却用非常不一样的设计思想来考虑这个问题。他们没有真正把人当成这个系统的一部分,没有像对待其它机器模块一样,提供具有良好抽象的界面给人。他们貌似觉得人应该可以多做一些事情,所以把纷繁复杂的程序内部结构暴露给人(包括他们自己)。所以人对“我能用这个程序干什么”这个问题总是很糊涂。当程序被修改之后,还经常需要让人的操作发生改变,所以这个系统对于人的可扩展性就差。通常程序员都考虑到机器各界面之间的扩展性,却没有考虑到机器与人之间界面的可扩展性。
举个例子。很多 Unix程序都有配置文件,它们也设置环境变量,它们还有命令行参数。这样每个用户都得知道配置文件的名字,位置和格式,环境变量的名字以及意义,命令行参数的意义。一个程序还好,如果有很多程序,每个程序都在不同的位置放置不同名字的配置文件,每个配置文件的格式都不一样,这些配置会把人给搞糊涂。经常出现程序说找不到配置文件,看手册吧,手册说配置文件的位置是某某环境变量 FOO 决定的。改了环境变量却发现没有解决问题。没办法,只好上论坛问,终于发现配置文件起作用当且仅当在同一个目录里没有一个叫 ”.bar” 的文件。好不容易记住了这条规则,这个程序升级之后,又把规则给改了,所以这个用户又继续琢磨,继续上论坛,如此反复。也许这就叫做“折腾”?他何时才能干自己的事情?
一个良好的界面不应该是这样的。它给予用户的界面,应该只有一些简单的设定。用户应该用同样的方法来设置所有程序的所有参数,因为它们只不过是一个从变量到值的映射(map)。至于系统要在什么地方存储这些设定,如何找到它们,具体的格式,用户根本不应该知道。这跟高级语言的运行时系统(runtime system)的内存管理是一个道理。程序请求建立一个对象,系统收到指令后分配一块内存,进行初始化,然后把对象的引用(reference)返回给程序。程序并不知道对象存在于内存的哪个位置,而且不应该知道。程序不应该使用对象的地址来进行运算。
所以我们看到,“对用户不友好”的背后,其实是程序设计的不合理使得它们缺少抽象,而不是用户的问题。这种对用户不友好的现象在 Windows,Mac,iPhone, Android 里也普遍存在。比如几乎所有 iPhone 用户都被洗脑的一个错误是“iPhone 只需要一个按钮”。一个按钮其实是不够的。还有就是像 Photoshop, Illustrator, Flash 之类的软件的菜单界面,其实把用户需要的功能和设置给掩藏了起来,分类也经常出现不合理现象,让他们很难找到这些功能。
如何对用户更加友好,是一两句话说不清楚的事情。所以这里只粗略说一下我想到过的要点:
- 统一:随时注意,人是一个统一的系统的一部分,而不是什么古怪的神物。基本上可以把人想象成一个程序模块。
- 抽象:最大限度的掩盖程序内部的实现,尽量不让人知道他不必要知道的东西。不愿意暴露给其它程序模块的细节,也不要暴露给人。“机所不欲,勿施于人”。
- 充要:提供给人充分而必要(不多于)的机制来完成人想完成的任务。
- 正交:机制之间应该尽量减少冗余和重叠,保持正交(orthogonal)。
- 组合:机制之间应该可以组合(compose),尽量使得干同一件事情只有一种组合。
- 理性:并不是所有人想要的功能都是应该有的,他们经常欺骗自己,要搞清楚那些是他们真正需要的功能。
- 信道:人的输入输出包括5种感官,虽然通常电脑只与人通过视觉和听觉交互。
- 直觉:人是靠直觉和模型(model)思考的,给人的信息不管是符号还是图形,应该容易在人脑中建立起直观的模型,这样人才能高效的操作它们。
- 上下文:人脑的“高速缓存”的容量是很小的。试试你能同时想起7个人的名字吗?所以在任一特定时刻,应该只提供与当前被关注对象相关的操作,而不是提供所有情况下的所有操作供人选择。上下文菜单和依据上下文的键盘操作提示,貌似不错的主意。
8.1.1.2. Unix 的缺点¶
谈 Linux,Windows 和 Mac http://www.yinwang.org/blog-cn/2013/03/07/linux-windows-mac Unix 的缺点 Unix Hater’s Handbook 操作系统 Multics,Lisp Machine Niklaus Wirth(也就是 Pascal 语言的设计者)的 Oberon 操作系统 去除头脑里的宗教,偏激,仇恨和鄙视。每次仇恨一个东西,你就失去了向它学习的机会。 Unix的缺陷 http://www.kuqin.com/linux/20120824/329555.html 通常所说的“Unix哲学”包括以下三条原则[Mcllroy]:
- 一个程序只做一件事情,并且把它做好。
- 程序之间能够协同工作。
- 程序处理文本流,因为它是一个通用的接口。
这三条原则当中,前两条其实早于 Unix 就已经存在,它们描述的其实是程序设计最基本的原则——模块化原则。任何一个具有函数和调用的程序语言都具有这两条原则。简言之,第一条针对函数,第二条针对调用。所谓“程序”,其实是一个叫 “main” 的函数(详见下文)。
所以只有第三条(用文本流做接口)是 Unix 所特有的。由此特性引发了很多问题。
8.1.1.3. 关于语言的思考 王垠¶
http://www.yinwang.org/blog-cn/2013/04/17/languages 多学几种语言
我今天想说其实就是,没有任何一种语言值得你用毕生的精力去“精通”它。“精通”其实代表着“脑残”——你成为了一个高效的机器,而不是一个有自己头脑的人。你必须对每种语言都带有一定的怀疑态度,而不是完全的拥抱它。每个人都应该学习多种语言,这样才不至于让自己的思想受到单一语言的约束,而没法接受新的,更加先进的思想。这就像每个人都应该学会至少一门外语一样,否则你就深陷于自己民族的思维方式。有时候这种民族传统的思想会让你深陷无须有的痛苦却无法自拔。
Scheme (Lisp)语言 的基于“S表达式”(S-expression)的语法,是世界上最完美的设计。
(case x
(-> (Short _) 1)
(-> (VeryLooooooooooooooooooooooooog _) 2))
8.1.2. 软件工程¶
8.1.2.1. 测试驱动开发¶
http://www.yinwang.org/blog-cn/2013/04/07/test-driven-dev
测试驱动的开发 (test-driven development) | 然而测试的构建,应该是在程序主体已经成形的情况下才能进行。如果程序属于创造性的设计,主体并未成形,过早的加入测试反而会大幅度的降低开发效率。所以当我给 Google 开发 Python 静态分析的时候,我几乎没有使用任何测试。虽然组里的成员催我写测试,但是我却知道那只会降低我的开发效率,因为这个程序在几个星期的过程中,被我推翻重来了好几次。要是我一开头就写上测试,这些测试就会碍手碍脚,阻碍我大幅度的修改代码。
测试的另一个副作用是,它让很多人对测试有一种盲目的依赖心理。改了程序之后,把测试跑一遍没出错,就以为自己的代码是正确的。可是测试其实并不能保证代码的正确,即使完全“覆盖”了也是一样。覆盖只是说你的代码被测试碰到过了,可是它在什么条件下碰到的却没法判断。如果实际的条件跟测试时的条件不同,那么实际运行中仍然会出问题。测试的条件往往是“组合爆炸”的数量级,所以你不可能测试所有的情况。唯一能可靠的方法是使用严密的“逻辑推理”,证明它的正确。
当然我并不是让你用 ACL2 或者 Coq 这样的定理证明软件。虽然它们的逻辑非常严密,但是用它们来证明复杂的软件系统,需要顶尖的程序员和大量的时间。即使如此,由于理论的限制,程序的正确性有可能根本无法证明。所以我这里说的“逻辑推理”,只是局部的,人力的,基本的逻辑推理。
这种做法的结果是,程序里出现大量的“特殊情况”和“创可贴”。把一个“虫子”按下去,另一个虫子又冒出来。忙活来忙活去,最后仍然不能让程序满足“所有情况”。其实能够“满足所有情况”的程序,往往比能够“满足特殊情况”的程序简单很多。这是一个很奇怪的事情:能做的事越多,代码量却越少。也许这就叫做程序的“美”,它跟数学的“美”其实是一回事。
美的程序不可能从修修补补中来。它必须完美的把握住事物的本质,否则就会有许许多多无法修补的特例。其实程序员跟画家差不多,画家如果一天到头蹲在家里,肯定什么好东西也画不出来。程序员也一样,蹲在家里面对电脑,其实很难写出什么好的代码。你必须出去观察事物,寻找“灵感”,而不只是写代码。在修改代码的时候,你必须用“心灵之眼”看见代码背后所表达的事物。这也是为什么很多高明的程序员不怎么用调试器(debugger)的原因。他们只是用眼睛看着代码,然后闭上眼,脑海里浮现出其中信息的流动,所以他们经常一动手就能改到正确的地方。
8.2. Oralce PL/SQL Best Practices Oralce PL/SQL最佳实践¶
8.2.1. 全局建议¶
- 应用程序层面的工作流程
- 构建单个程序的工作流程
8.2.1.1. 应用程序层面的工作流程¶
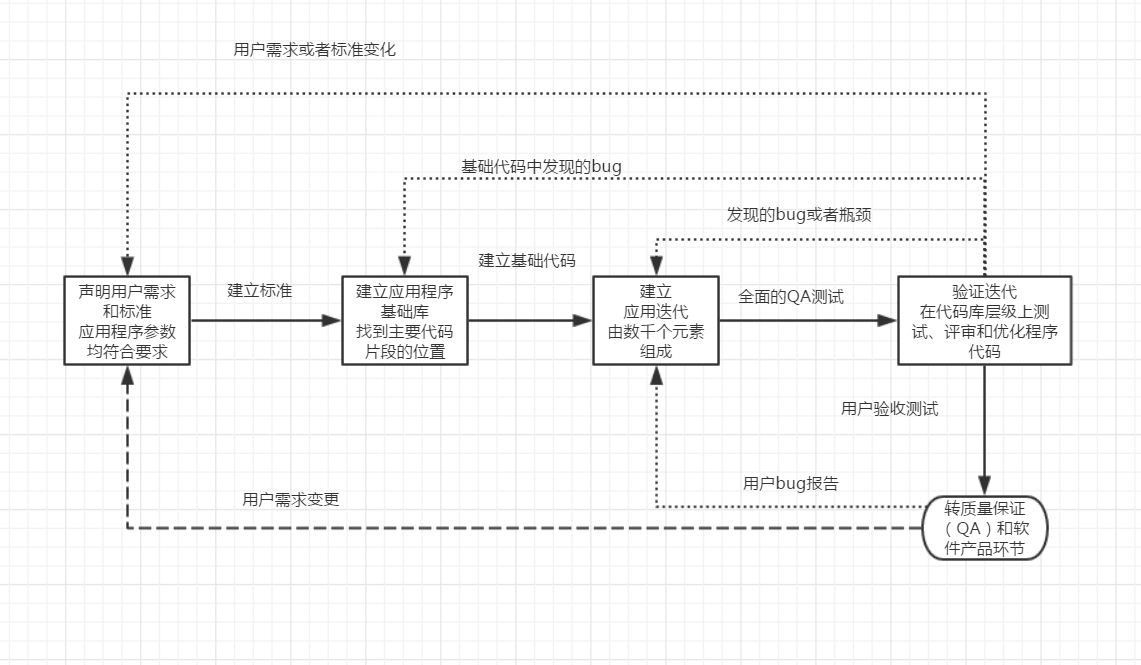
8.2.1.1.1. 步骤1:定义需求和标准¶
变更是需求收集工作的基本特征。能做的最好的事情就是集中力量,完成此时此刻的应用程序的明确功能。
站在用户的立场去考虑他们合乎逻辑的真实需要。
需求确定应用于每个程序的标准; 命名规范和编码标准
团队的每个成员以类似的风格编写程序代码。
- SQL访问
- SQL语句是程序代码中最易变的元素,会随着表结构和表之间关系随时变化。 查询、更新和其他SQL操作是导致大部分应用程序性能问题的根源。 对于PL/SQL程序代码中的SQL语句,需要预先设定在程序代码中使用SQL的时间、位置和方式。
- 错误管理
- 对错误的抛出、处理和传递方式要予以规范,否则当问题出现时,用户将很难理解如何处理问题,开发人员调试和修改应用程序会更加困难。
8.2.1.1.2. 步骤2:建立应用程序基础¶
- 建立支持这些规则能够被遵循的正式过程
- 提出清晰定义的流程,以及支持工具,让开发人员可以毫不费力地遵循这些规则。
- 规则实现自动化
- 让规则能自动执行。
- 命名规范和编码标准
- 团队的每个成员以类似的风格编写程序代码。创建代码模板和代码片段供参考。
- SQL访问
- SQL语句是程序代码中最易变的元素,会随着表结构和表之间关系随时变化。 查询、更新和其他SQL操作是导致大部分应用程序性能问题的根源。 对于PL/SQL程序代码中的SQL语句,需要预先设定在程序代码中使用SQL的时间、位置和方式。 把数据访问当作一个服务,而不是当作需要反复编写的代码。 SQL使用规则:不要编写它!
- 错误管理
- 对错误的抛出、处理和传递方式要予以规范,否则当问题出现时,用户将很难理解如何处理问题,开发人员调试和修改应用程序会更加困难。 实现应用程序范围层面的,一致性错误日志、错误抛出和处理机制的最佳方式是,使开发团队使用单个、共享的软件包(所使用的数据库表是经过精心设计的)来完成这个任务。
8.2.1.1.3. 步骤3:创建下一个应用程序迭代¶
8.2.1.2. 构建单个程序的工作流程¶
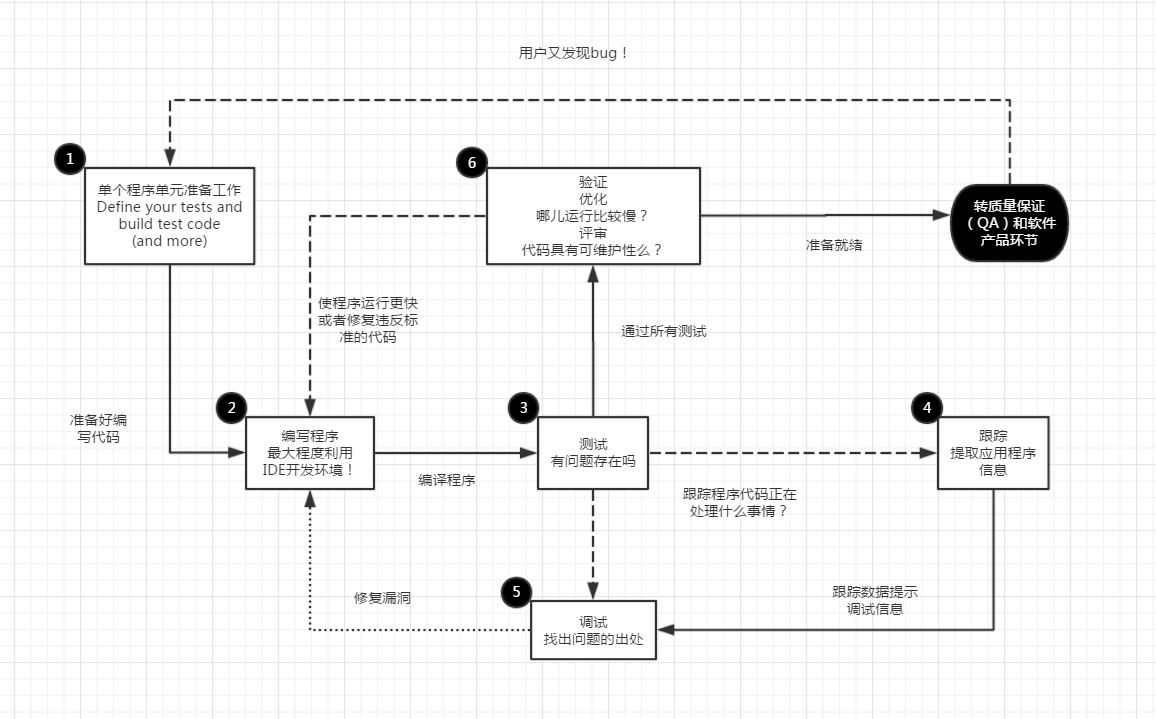
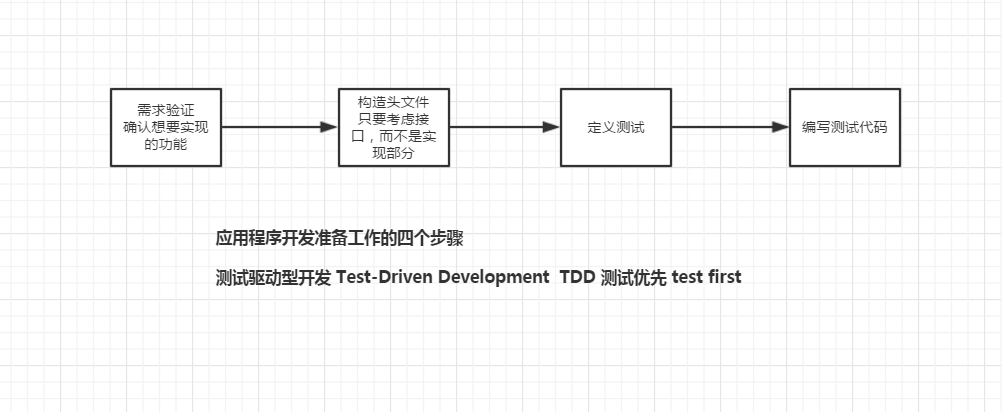
步骤1:准备创建程序 | 验证用户需求 | 构建程序头 | 定义测试 | 创建测试代码
步骤2:创建程序的一个迭代
步骤3:测试程序迭代
步骤4:跟踪程序的运行
步骤5:程序调试
步骤6:验证程序:优化和评审
不急于求成是实现最佳实践必需的素质